Advanced Operating Systems
Operating System Ideas
in the AI Era
Abstraction, resource management, scheduling, protection, and memory
Lecture 2 draft | Reading-driven slides
Not Just Memory
The real question is: where do OS ideas reappear in the AI era?
Classic OS manages processes / pages / files / devices
AI systems manage requests / agents / context / KV cache / tools
What Is LLM Inference?
Training
Update model weights. Offline, expensive, and often multi-day or multi-month.
Goal: learn the parameters.
Inference
Keep weights fixed. Given a prompt, generate output one token at a time.
Goal: low latency, high throughput, controlled cost.
OS perspective: inference is an online serving system, not a single neural-network call.
Example: when 500 students ask ChatGPT questions during office hours, the system must decide which requests run together, how much GPU memory each gets, and how to keep latency acceptable.
How Does a Large Model Answer Your Question?
A model does not write the whole answer at once; it repeatedly predicts the next token.
Step 1: Turn Text Into Tokens
User input:
Explain virtual memory.
The model does not directly process strings; it processes token IDs.
Tokenization
Explain virtual memory.Embedding
Each token ID becomes a vector that enters the Transformer.
What Is a Transformer?
Citation: Vaswani et al., Attention Is All You Need, Sections 1 and 3.
Inside One Transformer Layer
Citation: Vaswani et al., Attention Is All You Need, Section 3.
Step 2: Next-Token Prediction
KV Cache Grows With the Generated Sequence
Step 3: Q / K / V by Example
Citation: Vaswani et al., Attention Is All You Need, Section 3.2.
Step 4: Why Do We Need KV Cache?
Without KV Cache
When generating token 1001, recompute K/V for the first 1000 tokens in every layer.
A lot of repeated work.
With KV Cache
Compute each token's K/V once, store it, and reuse it in later decoding steps.
Trade memory for time.
KV cache is the working set of inference: longer context and more concurrent requests require more GPU memory.
A Full Answer Is Generated Like This
Input: "Explain virtual memory."
1. predict "Virtual"
2. context += "Virtual"; predict " memory"
3. context += " memory"; predict " is"
4. context += " is"; predict " an"
5. ... repeat until stop token
Every step reads the historical KV cache. Longer answers make the cache larger; more users make it harder to manage.
Why Does Inference Look Like an OS Problem?
Citation: Stoica et al., A Berkeley View of Systems Challenges for AI, Sections 3-4.
OS Idea 1
Abstraction
Turn complex, heterogeneous, changing machinery into stable interfaces
Abstraction: From OS to AI
| Classic OS | Abstraction | AI-era equivalent |
|---|---|---|
| CPU | Process / thread | LLM request / agent task |
| Physical memory | Virtual memory | Context window / KV cache blocks |
| Disk / devices | File descriptor | Tool handle / API capability |
| Network | Socket | Model endpoint / MCP server / remote tool |
| Kernel services | Syscalls | Agent kernel calls: memory, storage, tool, LLM |
A Key Question
Imagine a travel agent that can read your calendar, book flights, pay with a card, and email receipts.
should the OS manage it like an ordinary app?
Or do we need a new agent OS abstraction?
Concrete Example: A Travel Agent Crosses Two Worlds
Citation: Mei et al., AIOS: LLM Agent Operating System, Figure 1 and Introduction.
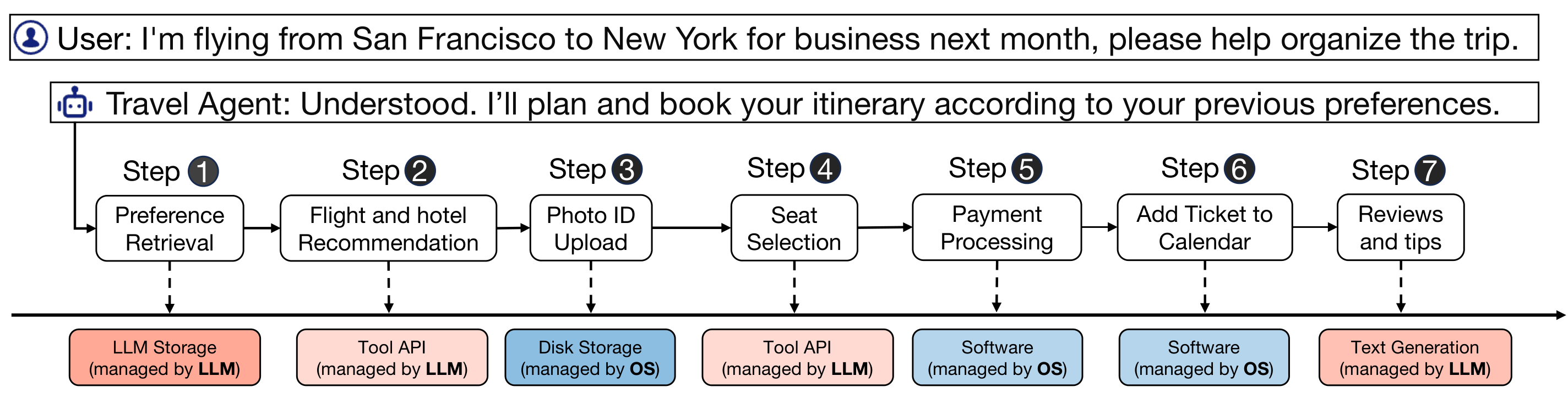
Problem
A single task touches preferences, APIs, disk upload, payment software, calendar software, and text generation.
What crosses boundaries?
Some services are LLM-managed; others are OS-managed. The agent must coordinate both safely.
Why OS ideas matter
This needs resource management, scheduling, access control, and auditability, not only prompting.
AIOS: The Agent Kernel Idea
Citation: AIOS GitHub README, Architecture Overview; Mei et al., AIOS, Sections 2-3.
Problem
Agents are no longer passive apps: they call LLMs, tools, files, memory, and external APIs.
Mechanism
AIOS inserts an agent kernel between applications and resources, exposing agent-level system calls.
Why it helps
Scheduling, context switching, memory, storage, tools, and access control move into one control plane.
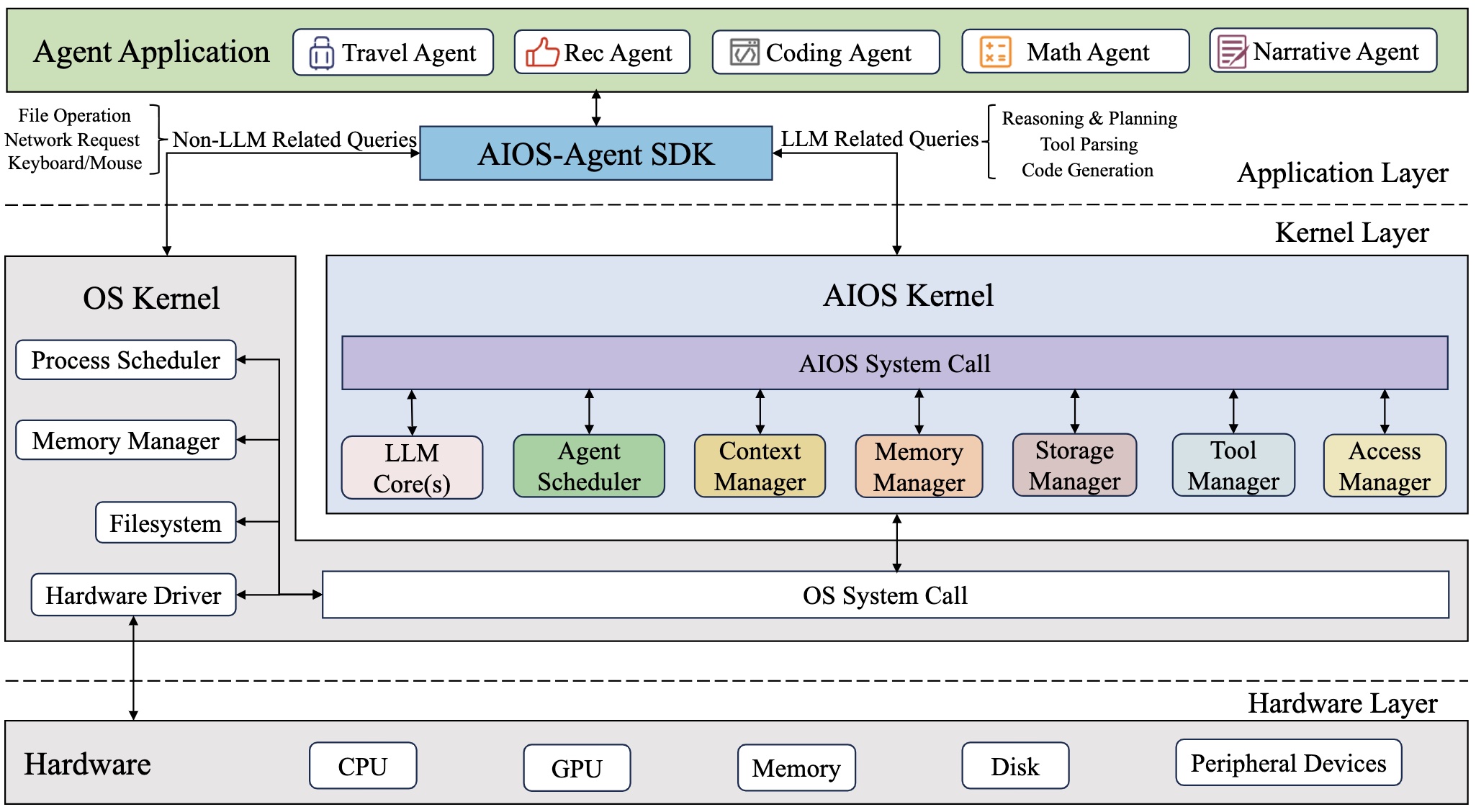
Original framing
README: AIOS “embeds large language model (LLM) into the operating system.”
README: the AIOS kernel is an “abstraction layer over the operating system kernel.”
OS interpretation
Agents are treated like applications; the AIOS Kernel exposes services for LLM, memory, storage, tools, and access control.
AIOS Modules: Agent Syscalls
Citation: AIOS GitHub README, “Modules and Connections”; Mei et al., AIOS, Sections 3.2-3.8.
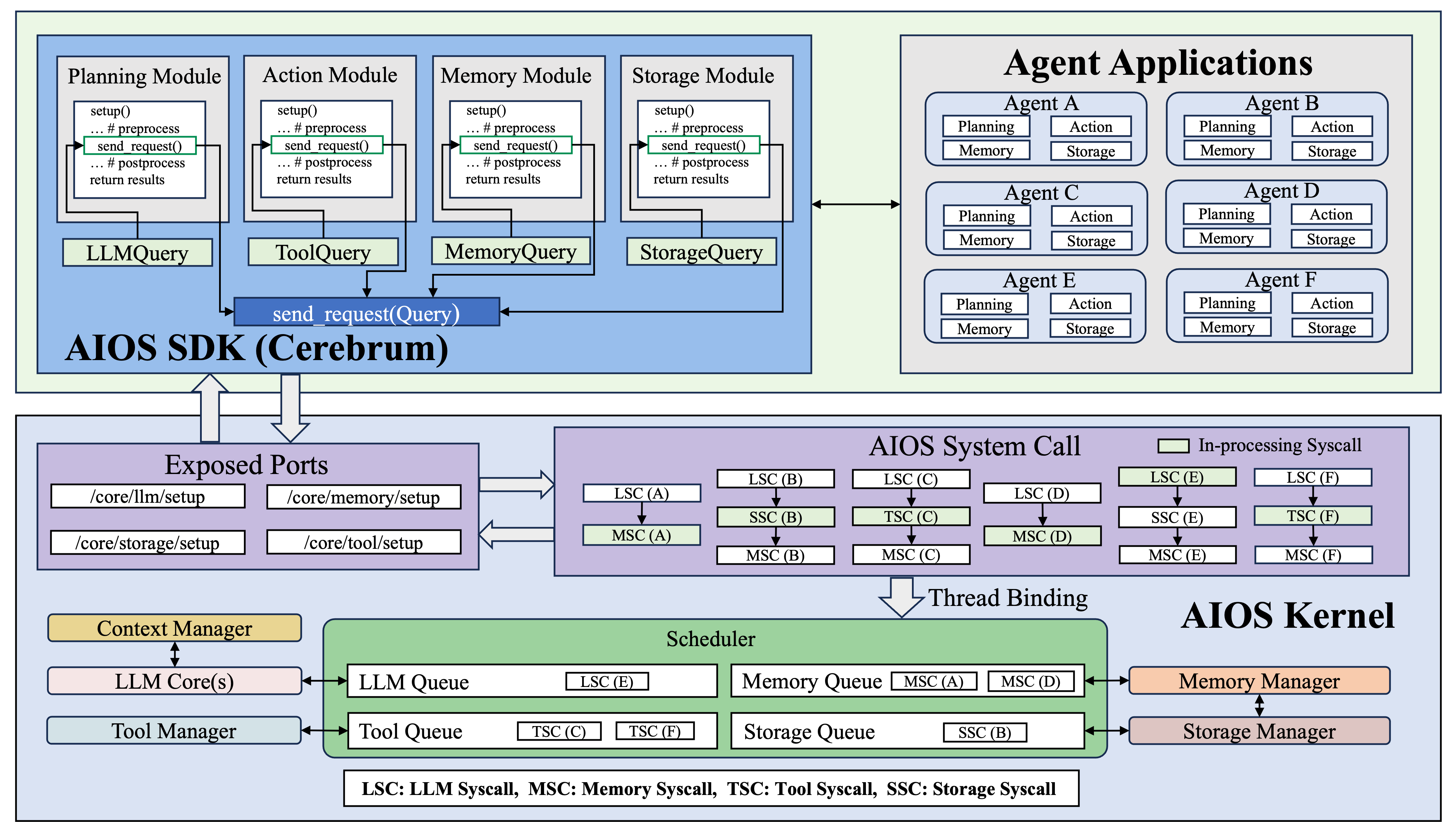
Read top down
Agent app calls SDK modules.
Middle layer
Calls become AIOS syscalls.
Kernel layer
Queues and managers control resources.
OS Idea 2
Resource Management
Scarce resources + many competitors + dynamic demand
What Resources Exist in AI Systems?
GPU Memory
Model weights, activations, and KV cache.
GPU Compute
Prefill is compute-heavy; decode is often memory-bound.
Context Window
Prompt, history, retrieved documents, and tool outputs.
Tool/API Budget
External API calls, cost, and rate limits.
Classic OS problems reappear: allocation, fragmentation, sharing, reclamation, accounting.
KV Cache: The Core Memory Object in LLM Inference
Citation: Kwon et al., Efficient Memory Management for Large Language Model Serving with PagedAttention, Sections 3-4.
When a token passes through each Transformer layer, that layer produces the token's Key and Value.
Example: after reading “The OS manages memory,” layer 1 stores K(The), V(The), K(OS), V(OS), K(manages), V(manages), K(memory), V(memory).
Each one is a numeric fingerprint, such as K(The) = [0.12, -0.48, ...], not the word itself.
Prefill: compute K/V for all prompt tokens and write them into cache.
Decode: for every new token, read all historical K/V and append the new token's K/V.
The next step reuses cached history instead of recomputing it.
This is a classic space-time tradeoff.
KV size = 2 x layers x heads x dim x seq_len x dtype
Output length is unknown, so KV cache grows dynamically during decode.
Words are shown in examples only as labels; the real cache stores numeric hidden vectors.
PagedAttention: Virtual Memory for KV Cache
Citation: Kwon et al., PagedAttention, Section 4.1.
Problem
Each request has unknown output length; preallocating max length wastes GPU memory, while dynamic growth fragments it.
Mechanism
Split KV cache into fixed-size blocks and use a block table to map logical token history to physical GPU blocks.
Why it helps
Requests can grow on demand, physical blocks need not be contiguous, and shared prefixes can reuse blocks.
| Virtual Memory | PagedAttention / vLLM | Why it matters |
|---|---|---|
| Virtual page | Logical KV block | The request sees a continuous token history |
| Physical frame | Physical KV block | GPU memory can be non-contiguous |
| Page table | Block table | Indirection from logical to physical blocks |
| Demand paging | Allocate KV blocks on demand | Reduce reserved waste |
| Copy-on-write | Prefix sharing | Beam search / parallel samples share prompt KV |
Logical History, Non-contiguous Physical Blocks
This Is OS Design, Not Just an AI Trick
Before
Reserve maximum output length, or grow dynamically and suffer fragmentation.
Result: low batch size, wasted GPU memory.
After
KV cache becomes fixed-size blocks mapped on demand.
The problem becomes block allocation plus scheduling.
Core idea: indirection buys flexibility.
OS Idea 3
Scheduling
Who runs first? For how long? When do we preempt?
What Must an LLM Serving Scheduler Handle?
Short request
“Translate this sentence.”
Latency matters most.
Long request
“Summarize this 200-page PDF.”
Throughput and memory footprint matter.
Agent request
Browse the web, write code, run tests, then respond.
Includes LLM calls, tools, and state.
Batching pressure
Larger batches improve throughput, but latency and memory can explode.
Prefill vs Decode
System point: LLM serving has phase-specific resource behavior; schedulers can exploit that difference.
Problem
Prefill and decode interfere when they share the same GPU pool: one is bulk prompt processing, the other is token-by-token streaming.
Mechanism
Separate queues, batch sizes, or GPU pools can be used for prefill and decode; some systems disaggregate the phases.
Why it helps
Better time-to-first-token for prompts, steadier token streaming for decode, and fewer long requests blocking short ones.
Prefill
Process the prompt and build the initial KV cache.
Usually more compute-heavy; affects time-to-first-token.
Decode
Generate one new token at a time while repeatedly reading and writing KV cache.
Usually more memory/bandwidth-sensitive; affects token streaming.
Advanced OS question: should these phases share the same GPUs, or should they be scheduled like different job classes?
Agents Also Need Context Switching
A normal program context switch saves registers, PC, and address-space state.
An LLM agent context switch may need to save:
- conversation/context state
- tool call progress
- intermediate generation state
- memory and retrieval state
AIOS motivation
If multiple agents share one LLM runtime, the system needs scheduling, suspension, resumption, fairness, and access control.
OS Idea 4
Protection
AI agents make security boundaries semantic
What Can a Traditional OS See?
How Do We Prevent It?
Problem
Prompt injection hides commands inside normal data, so the dangerous part is semantic, not just a syscall pattern.
Mechanism
Route tool calls through capability checks, data-flow checks, sandboxing, and human approval for high-risk actions.
Why it helps
The agent can still use tools, but the runtime enforces least privilege and blocks unsafe data movement.
Computer-use Agents Need a Stronger Boundary
Citation: AIOS GitHub README, “Computer-use Specialized Architecture.”
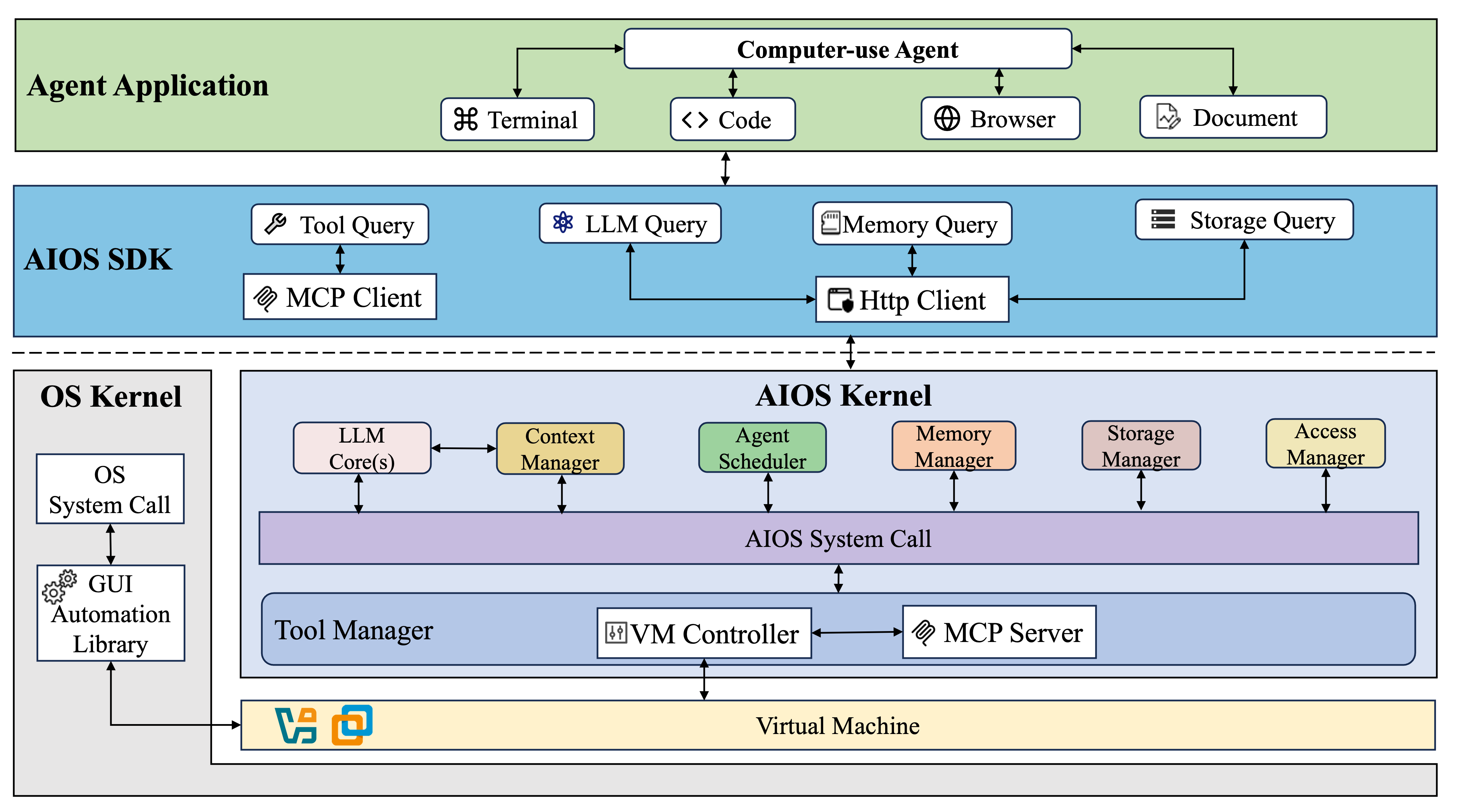
Original point
README: the Tool Manager is redesigned to include a VM Controller and MCP Server.
README: this creates a sandboxed environment for computer interaction.
OS interpretation
For computer-use agents, tool access becomes device access. The runtime needs isolation, mediation, and auditability.
OS Idea 5
Memory Hierarchy
The context window is the new scarce memory
Example: The Agent Cannot Fit Everything in Context
Citation: Packer et al., MemGPT, Sections 1-2.
Problem
The context window is small. A book, old notes, and a long conversation cannot all stay in the prompt.
Mechanism
Keep active information in main context; summarize or store old information externally; retrieve relevant facts when needed.
Why it helps
The agent behaves as if it has long-term memory while still using a fixed-context model.
MemGPT as Virtual Context Management
Citation: Packer et al., MemGPT: Towards LLMs as Operating Systems, Sections 1-2.
Why Attention Becomes a Systems Problem
Citation: Vaswani et al., Attention Is All You Need, Sections 1 and 3.2.
How the Readings Fit Together
| Paper | Role in lecture | Suggested section |
|---|---|---|
| Berkeley View | Why AI is a systems problem | Abstract, Sections 3-4 |
| Attention Is All You Need | Q/K/V and Transformer background | Abstract, Sections 1, 3.2 |
| PagedAttention | Virtual memory / paging applied to KV cache | Sections 3-4 |
| MemGPT | Context window as memory hierarchy | Sections 1-2 |
| AIOS | Agent kernel: scheduling, context, memory, access | Abstract, Sections 2-3 |
Discussion Questions
Q1. Is PagedAttention a successful transfer of an OS idea, or an application-specific hack?
Q2. Should agent tool permissions be controlled by prompts, or by a kernel/control plane?
Q3. Who should decide the context-window replacement policy: the LLM, the runtime, or the user?
Q4. Is AIOS closer to a monolithic kernel or a microkernel?
Takeaways
- LLM inference is an online systems problem, not just a model problem.
- AI systems amplify core OS questions: resources, concurrency, isolation, and abstraction.
- PagedAttention shows how virtual-memory ideas transfer to GPU KV cache.
- MemGPT turns the context window into a managed memory hierarchy.
- AIOS treats agents as a new workload that needs kernel services.
AI does not make OS obsolete; it makes OS ideas central again.
Questions?
Next: deeper dive into one case study
Option A: PagedAttention / KV cache memory manager
Option B: Agent OS / sandboxing / access control
Option C: MemGPT / long-term agent memory